What you see here is the last week’s worth of links and quips I have shared on LinkedIn, from Monday through Sunday.
For now I’ll post the notes as they appeared on LinkedIn, including hashtags and sentence fragments. Over time I might expand on these thoughts as they land here on my blog.
2023/11/07: A contextual-advertising lesson
Here’s a lesson about AI risk management, in the context of adtech.
When it comes to AI, your ideal outcome is that the models’ prediction is correct : the bot makes the right purchase (good price and quantity), chooses the right ad (so the person clicks it), puts the document in the right bucket (“this is relevant to this trial”), and so on.
The thing is, every AI model will be wrong some portion of the time. If “be right” is first place, a close second is “be inoffensively wrong.” Like when you see an ad that’s not quite correct but you still understand why it was shown to you.
The worst-case scenario? That’s when the AI model’s prediction is offensive and/or causes harm. Maybe the model tells someone to deliver the incorrect drug dosage. Or a generative AI says that it supports slavery and genocide (https://www.tomshardware.com/news/google-bots-tout-slavery-genocide).
My colleague and fellow AI expert Ariel Gamiño sent me a concrete example: the ad for a bridge-building game … that appears on an article about someone who died because a bridge broke:
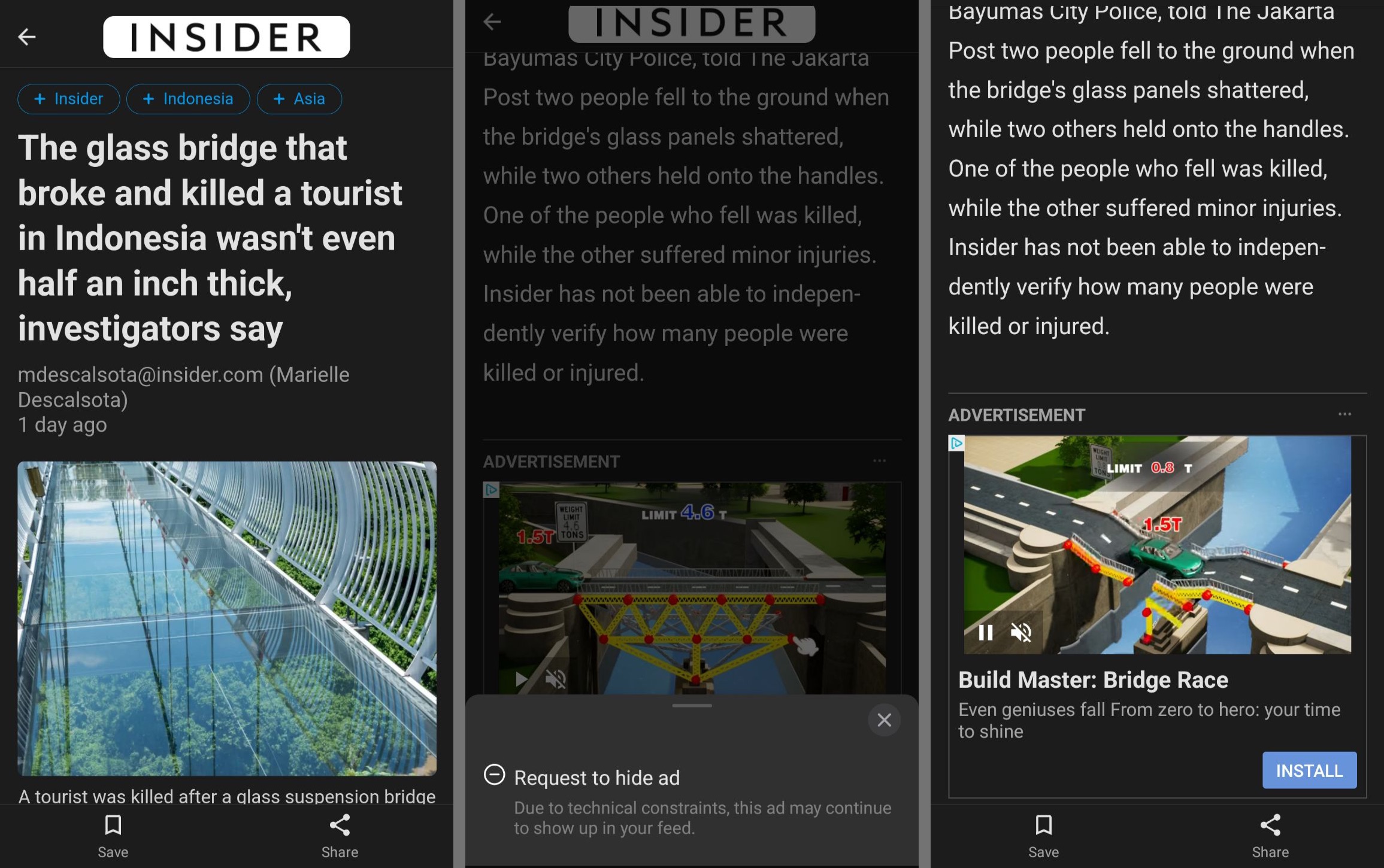
Our first question was, “Why did this ad appear?” We reasoned that this was a contextual ad, which relies on the content of the current page rather than the browsing history of the reader.
We think contextual ads are great. They work wonders for both data privacy and technology spend. (I wrote about that here, in the context of streaming video ads).) But they are still not perfect. While this ad has a logical connection to the page’s context (“bridge”), it lacks any social understanding.
All of this takes us back to the risk management angle. My usual refrain of “keep an eye on the model’s outputs” is not always feasible in the high-speed, real-time world of serving ads. So the next-best thing is to invest the time and effort during R&D to surface anything that may trip up the model.
Remember: an AI model has no definition of “appropriate.” It’s up to you, the humans building it, to establish guardrails that support cultural context.
2023/11/09: The computer says that the human says no
Remember the old “computer says no” sketches from Little Britain? That catchphrase comes up a lot in discussions of AI and other tech-based decision systems.
(For those who haven’t seen them: a receptionist named Carol simply accepts the answer her computer gives her, even when it makes little sense. And she’s unable/unwilling to explain that answer to the people who are affected.)
Some companies have developed this awful habit of building tools and then abdicating responsibility for those tools’ actions. Case in point:
“Why Banks Are Suddenly Closing Down Customer Accounts” (NY Times)
As is the pattern, the Dear John letter from the bank offered no explanation. But when he went into the branch, the frustrated manager said more than he was supposed to. “The answer was: ‘Don’t ask me. Ask the computer that flagged you,’” Mr. Ferker said.
(Kafka had nothing on modern-day corporations, it seems.)
Let’s take a moment to remember that every AI system is:
- built by people …
- … based on decisions made by people …
- … fueled by datasets and features that were chosen by people
Every AI model packages up all of those decisions and is effectively a proxy of those who built it. That includes the decision to not permit a human to override the model. There is, therefore, at least one person behind every action a model takes. Let’s not fall for the idea that “the model said so.”
What can you do, if you want to improve transparency around your company’s AI efforts?
1/ Keep track of every decision that was made about the model: what features to use, what training data to use, what training data to exclude. And be willing to explain all of that to regulators and affected parties.
2/ Create mechanisms for team members to override the model when it’s misbehaved. If the model has acted in error, make sure that someone is able to right the wrong.
3/ Establish points of contact for affected people to contact those team members when things go wrong. Because it’s one thing to be mistakenly flagged by a model. Quite another to have no way to address the issue.
2023/11/10: Know what you’re selling
Just a reminder: if your product is a thin wrapper around someone else’s API (or service, or tool) then you are effectively a reseller of said API.
The plus side? You get to launch a product very quickly, with minimal time/effort/money invested in R&D.
The minus side? A slight change in that underlying API can wreck your company overnight. The parent company can remove your access, or launch a competing product. (“Hey, thanks for helping us sort out some use cases that people like.”)
So is the risk/reward tradeoff worth it? That depends on your exit strategy…
“OpenAI Signals That It’ll Destroy Startups Using Its Tech to Build Products” (Futurism)