
My latest book: Twin Wolves: Balancing risk and reward to make the most of AI

(Photo by Peter Herrmann on Unsplash)
This screen cap is from a newsletter I was working on a couple of days ago (January 2023):
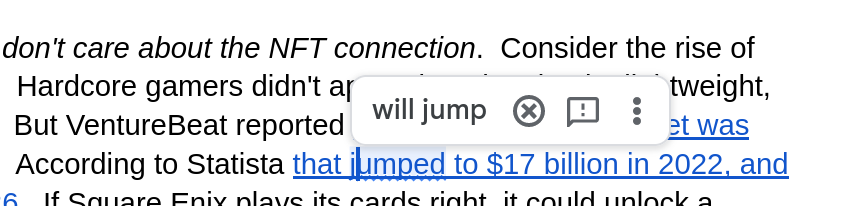
The Google Docs grammar check flagged that use of "jumped" because it ... held the end of 2022 as still being in the future.
Why did this happen? Well, I figure the model (or system of models) behind the grammar check hadn't been updated for the new year. Which is no big deal! I still think Google Docs is great, and the grammar checker is usually helpful.
(Emphasis on "usually," but I digress.)
Still, this event serves as a reminder of three key points:
1/ An ML model can and will be wrong now and then. The model's entire experience and world view are based on its training data. It makes probabilistic statements based on what it has seen before.
(In this case, I'd guess that it hadn't seen anything refer to 2022 in the past.)
2/ It's OK for your model to be wrong. The trick is to determine how wrong it can be, before you have a problem. A grammar check? Lots of room. A trading decision? Very little room.
(Solomon Kahn recently highlighted this point when he said that, sometimes, "mostly right" is just fine. This is why you want to perform a risk assessment as part of your model planning processes...)
3/ Models can't afford to be static. The world still changes, if nothing else. That means you should pull fresh data and retrain your models now and then.
(When is the last time you retrained your core ML models? Has the outside world changed enough to merit a refresh?)
Revisiting the idea of noncompete clauses
A quick on the FTC's recent proposal, and a link to something I wrote almost a decade ago
The top failure modes of an ML/AI modeling project (Part 1)
A short list of ways an ML/AI modeling project can go off the rails